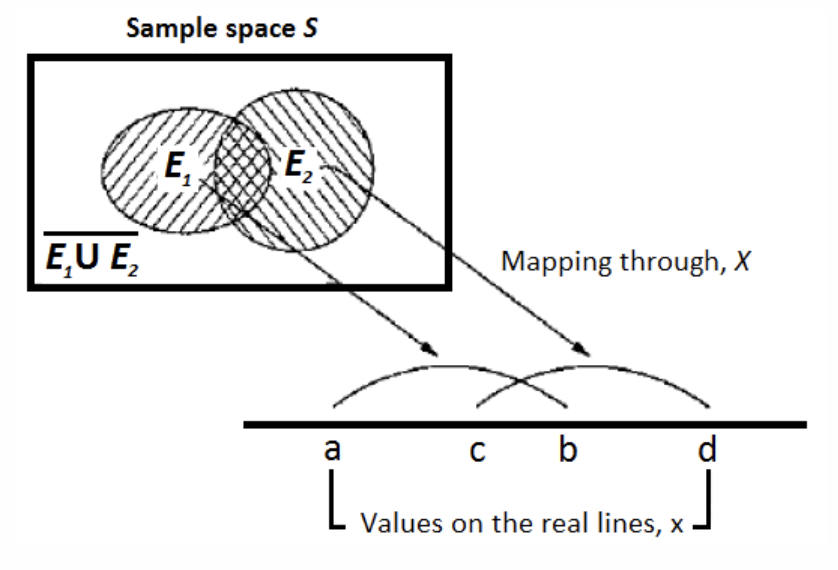
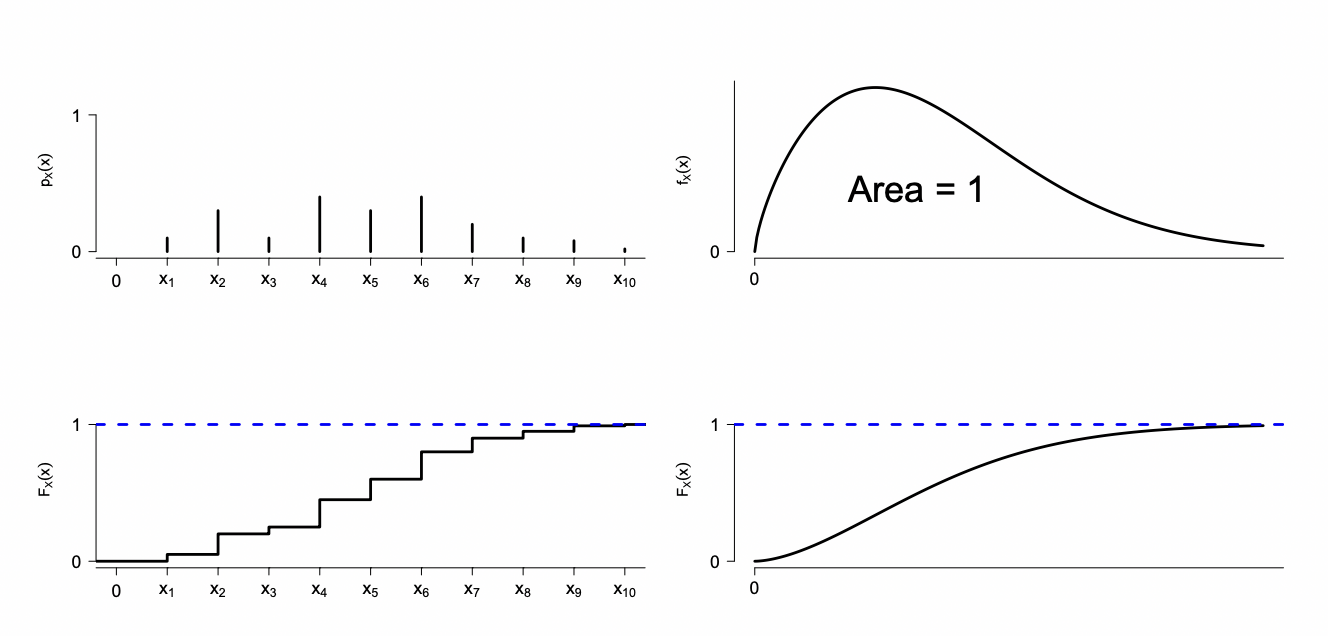
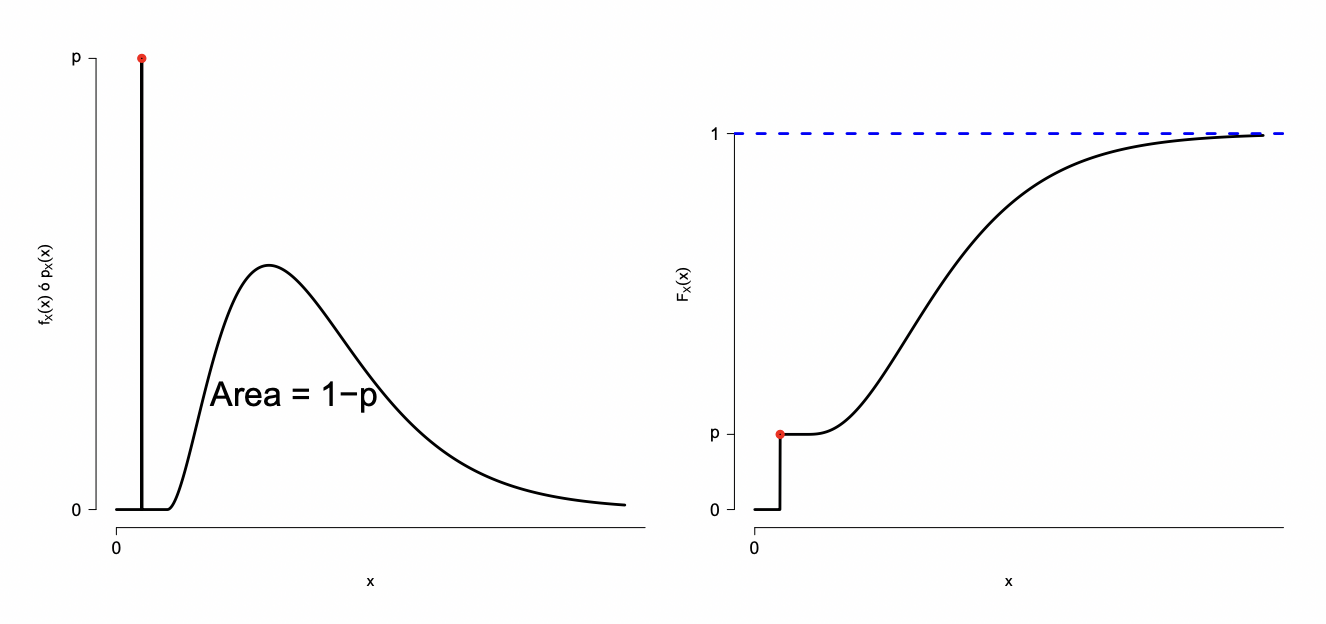
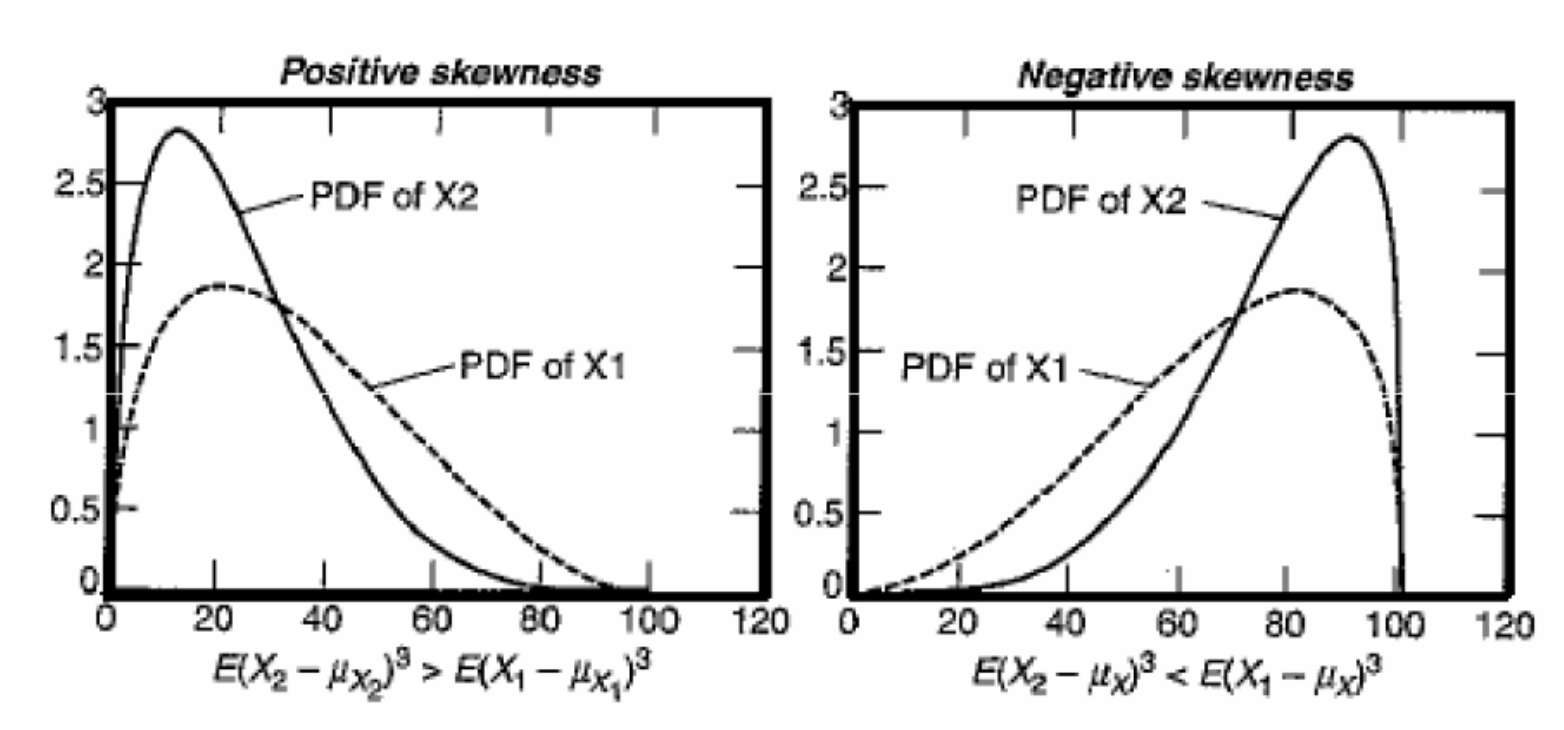
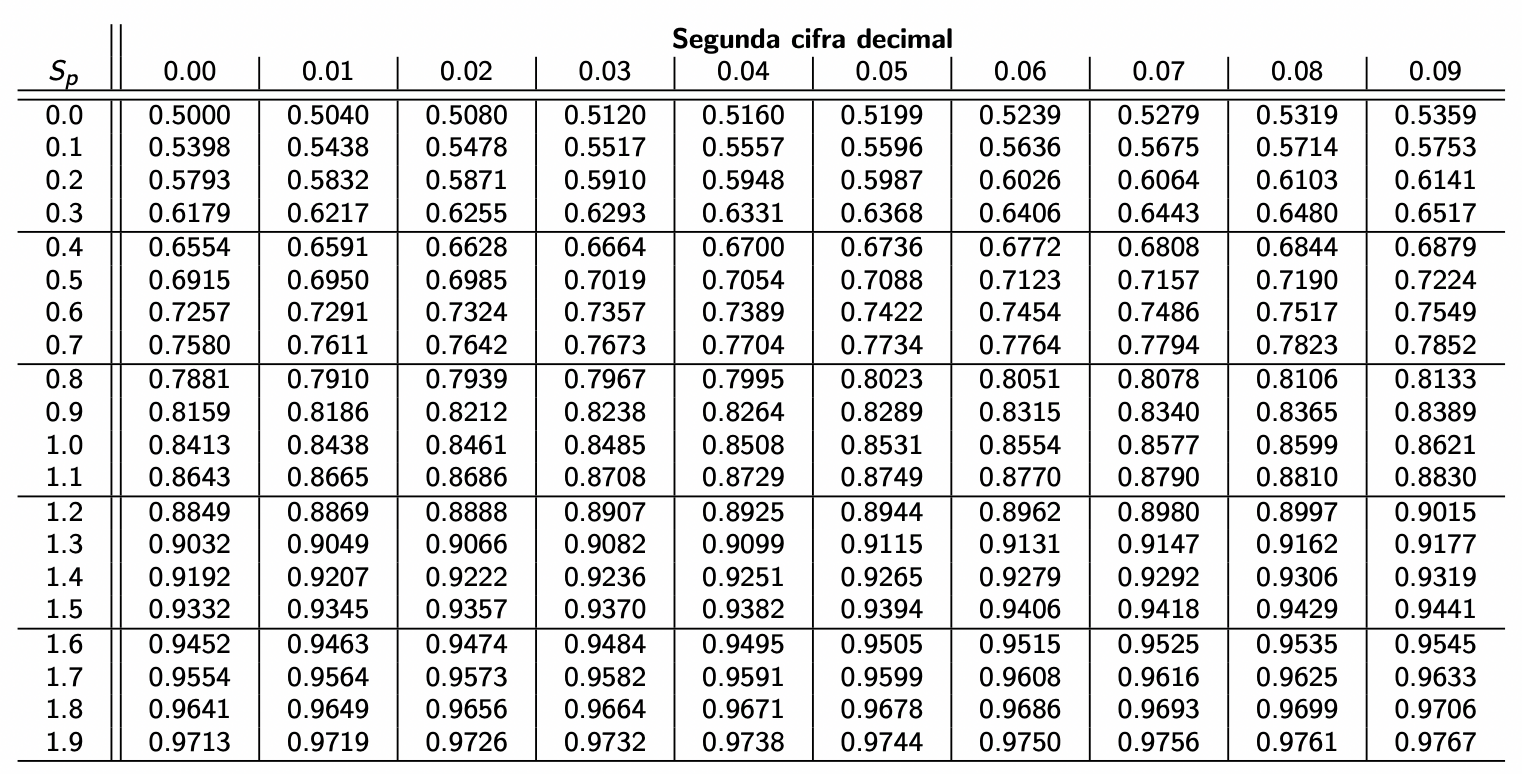
Una variable aleatoria es el vehículo matemático para representar un evento en términos analíticos. El valor de una variable aleatoria puede estar definida para un conjunto de posibles valores.
Si X es una variable aleatoria, entonces
X=x,X<x,X>x
representa un evento, donde (a<X<b) es el rango de valores posibles de X.
La asignación numérica puede ser natural o artificial.
Formalmente, una variable aleatoria puede ser considerada como una función o regla sobre los eventos del espacio muestral a un sistema numérico (o línea real).
Para los valores o rango de valores que puede tomar una variable aleatoria tienen asociados una probabilidad especifica o medidas de probabilidad. La regla que asigna las medidas de probabilidad se denomina distribución o ley de probabilidad.
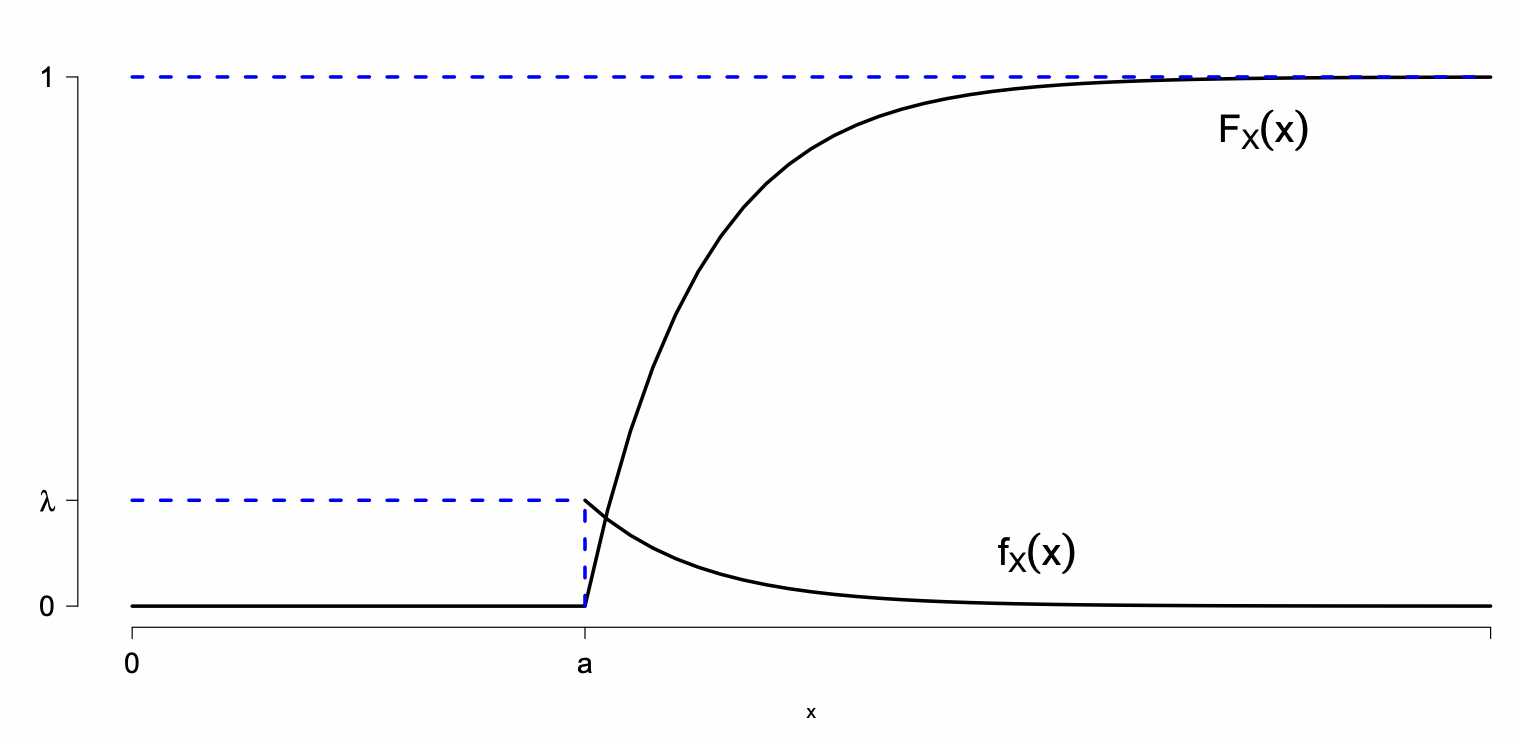
Si X es variable aleatoria, la distribución de probabilidad puede ser descrita por su función de distribución de probabilidad acumulada denotada por:
FX(x)=P(X≤x) para todo x∈R
Si X es una variable aleatoria discreta, entonces esta función puede ser expresada a través de la función de probabilidad "puntual" denotada por
pX(x)=P(X=x)
Así,
FX(x)=xi≤x∑P(X=xi)=xi≤x∑pX(xi)
con xi∈ΘX (soporte de X).
Ahora, si X es una variable aleatoria continua, las probabilidades están asociadas a intervalos de x. En este caso se define la función de densidad fX(x) tal que
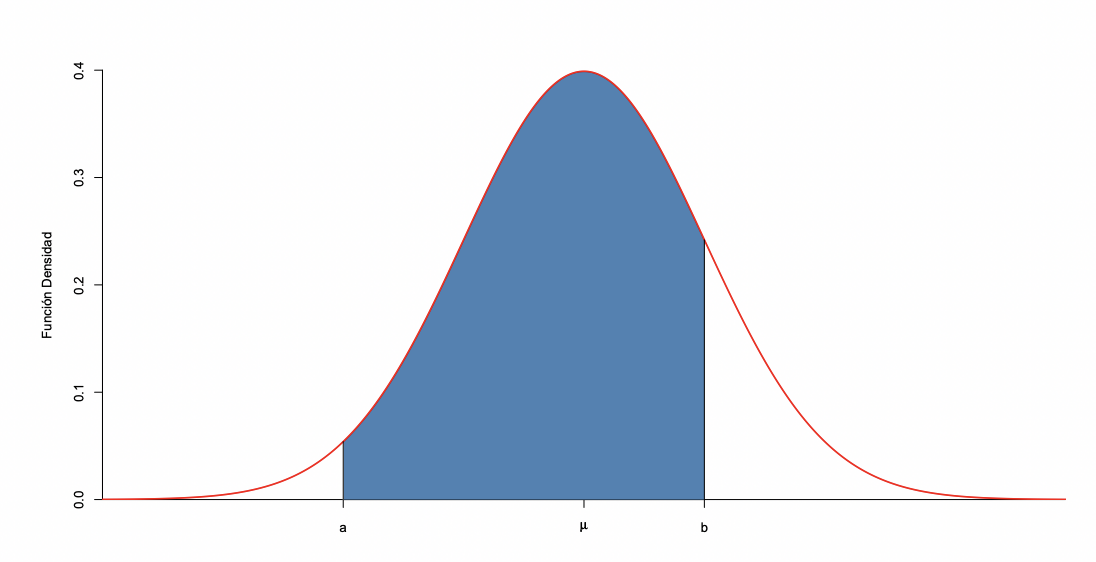
P(a<X≤b)=∫abfX(x)dx
y
FX(x)=P(X≤x)=∫−∞xfX(t)dt
con
fX(x)=dxdFX(x)
Notar que
P(x<X≤x+dx)=fX(x)dxCaso discreto y continuoCaso mixto
Una variable aleatoria puede ser descrita totalmente por su función de distribución de probabilidad o de densidad, o bien por su función de distribución de probabilidad acumulada. Sin embargo, en la práctica la forma exacta puede no ser totalmente conocida.
En tales casos se requieren ciertas "medidas" para tener una idea de la forma de la distribución.
En el rango de posibles valores de una variable aleatoria, existe un interés natural con respecto a los valores centrales, por ejemplo, el promedio.
Consideremos una variable aleatoria X con soporte ΘX.
Como cada valor de ΘX tiene una medida de probabilidad, el promedio ponderado es de especial interés.
Al promedio ponderado se le llama también valor medio o valor esperado de la variable aleatoria X. Para una variable aleatoria X se define el valor esperado, μX, como:
μX=E(X)=⎩⎨⎧x∈ΘX∑x⋅pX(x),∫−∞∞x⋅fX(x)dx, Caso Discreto Caso Continuo
En resumen, el valor esperado de una variable aleatoria es un valor promedio que puede ser visto como un indicador del valor central de la distribución de probabilidad, por esta razón se considera como un parámetro de localización.
Por otra parte, la mediana y la moda de una distribución también son parámetros de localización que no necesariamente son iguales a la media.
Nota
Cuando la distribución es simétrica, estas tres medidas son parecidas.
La noción del valor esperado como un promedio ponderado puede ser generalizado para funciones de la variable aleatoria X.
Dada una función g(X), entonces el valor esperado de esta puede ser obtenido como:
E[g(X)]=⎩⎨⎧x∈ΘX∑g(x)⋅pX(x),∫−∞∞g(x)⋅fX(x)dx, Caso Discreto Caso Continuo
La función generadora de momentos de una variable aleatoria X se define como
MX(t)=E[exp(tX)]
Esta función puede no estar definida para algunos valores de t, pero si existe en un intervalo abierto que contenga al cero, entonces esta función tiene la propiedad de determinar la distribución de probabilidad de X.
Cuando esto último ocurra, esta función permite obtener el r-ésimo momento de X de la siguiente forma
Es de interés cuantificar el nivel de dispersión que tienen una variable aleatoria con respecto a un valor de referencia. Por ejemplo, nos podría interesar la distancia esperada de los valores de una variable aleatoria X con respeto al valor esperado μX, es decir, E[(X−μX)].
Esta idea de dispersión tiene el problema que siempre da como resultado cero.
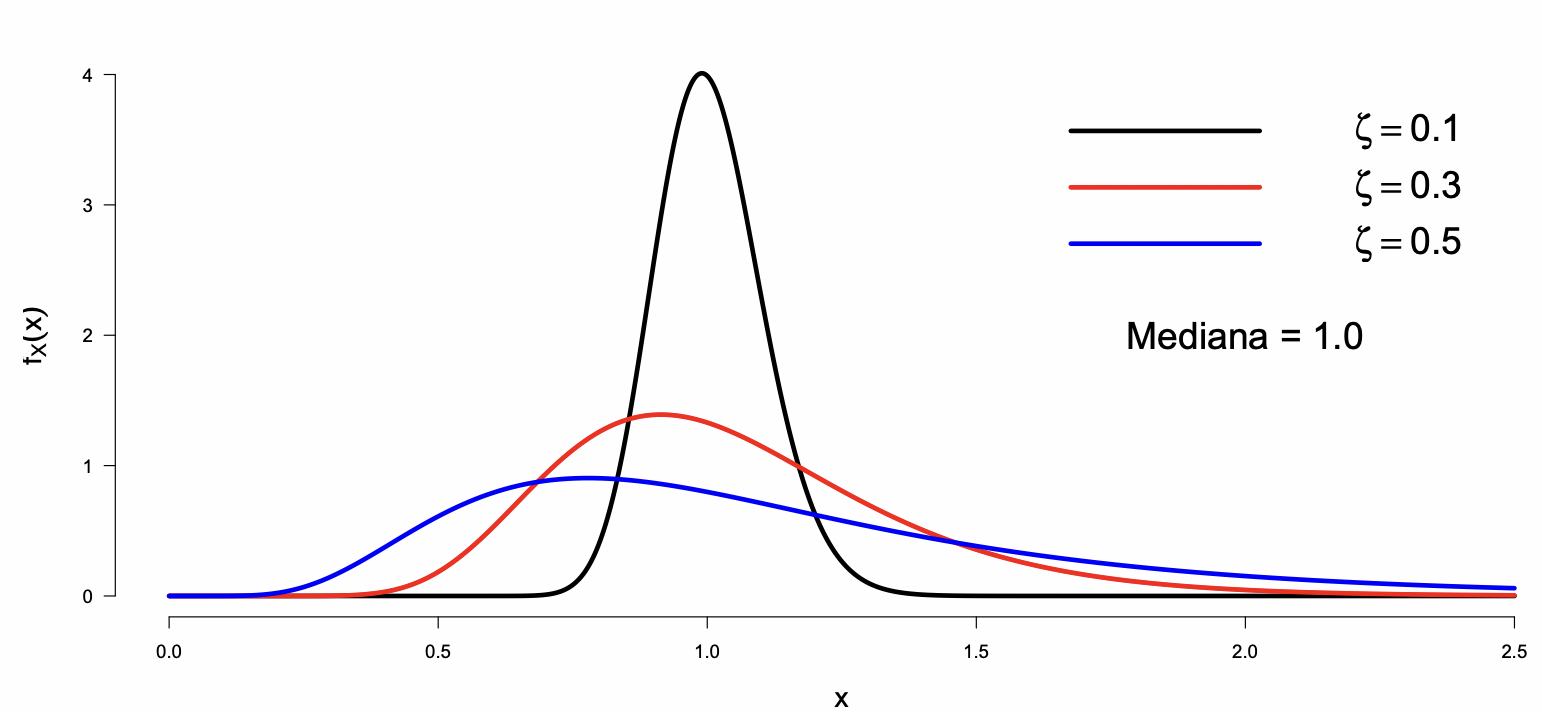
Se dice que X sigue una ley de probabilidad Log-Normal si su función de densidad esta dada por
fX(x)=2π1(ζx)1exp[−21(ζlnx−λ)2],x≥0
Donde,
λ=E(lnX) y ζ=Var(lnX)
Algunas propiedades:
lnX∼Normal(λ,ζ)
μX=exp(λ+ζ2/2)
Mediana =exp(λ)
E(Xk)=exp(λk)⋅MZ(ζk), con Z∼Normal(0,1)
σX2=μX2(eζ2−1)
ζ=ln(1+δX2)
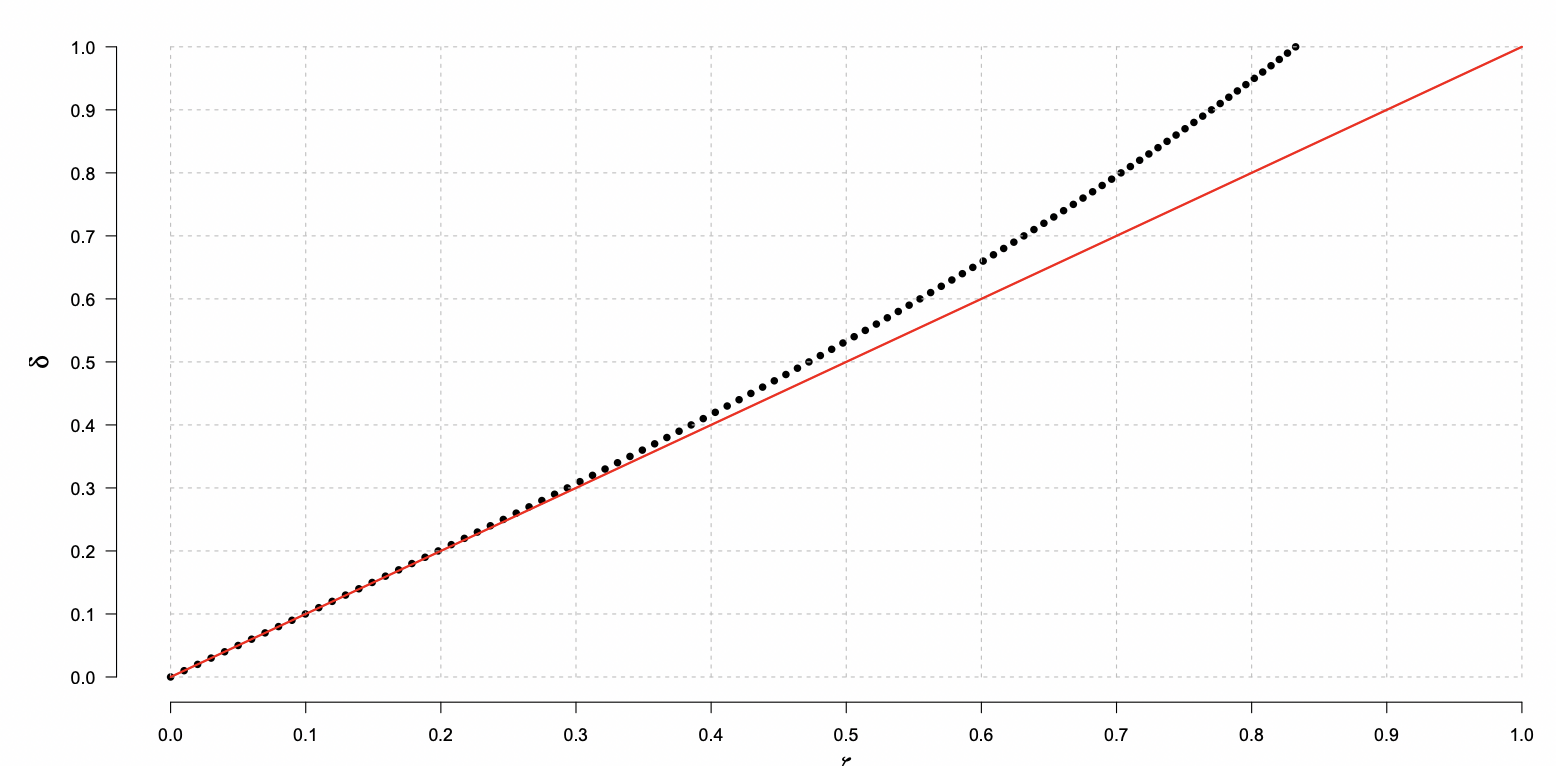
Distribución log-normal
Nota
En la distribución log-normal, la relación entre el coeficiente de variación (c.o.v.) δ y el parámetro ζ es tal que si los dos son suficientemente pequeños, entonces δ≈ζ.
En las más diversas áreas de la Ingeniería, a menudo los problemas involucran la ocurrencia o recurrencia de un evento, el cual es impredecible, como una secuencia de "experimentos". Por ejemplo:
Para un día de lluvia, ¿colapsa o no un sistema de drenaje?
Al comprar un producto, ¿éste satisface o no los requerimientos de calidad?
Un alumno ¿aprueba o reprueba el curso?
Notar que hay sólo dos resultados posibles para cada "experimento". Las variables descritas pueden ser modeladas por una secuencia Bernoulli, la cual se basa en los siguientes supuestos:
Cada experimento, tiene una de dos opciones: ocurrencia o no ocurrencia del evento.
La probabilidad de ocurrencia del evento ("éxito") en cada experimento es constante (digamos p).
Los experimentos son estadísticamente independientes.
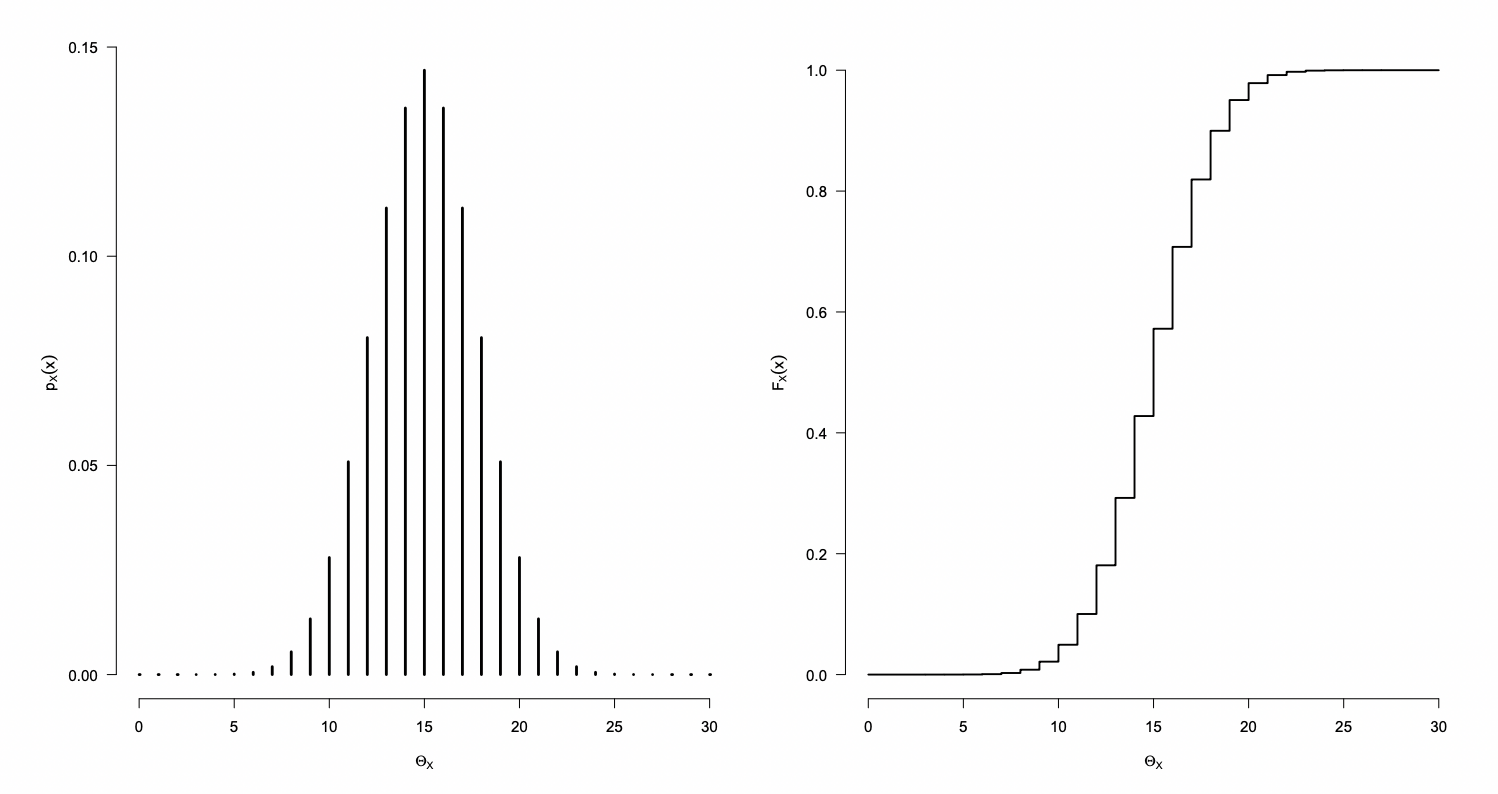
Dada una secuencia Bernoulli, si X es el número de ocurrencias del evento éxito entre los n experimentos, con probabilidad de ocurrencia igual a p, entonces la probabilidad que ocurran exactamente x éxitos en los n experimentos esta representada por la distribución Binomial, descrita por
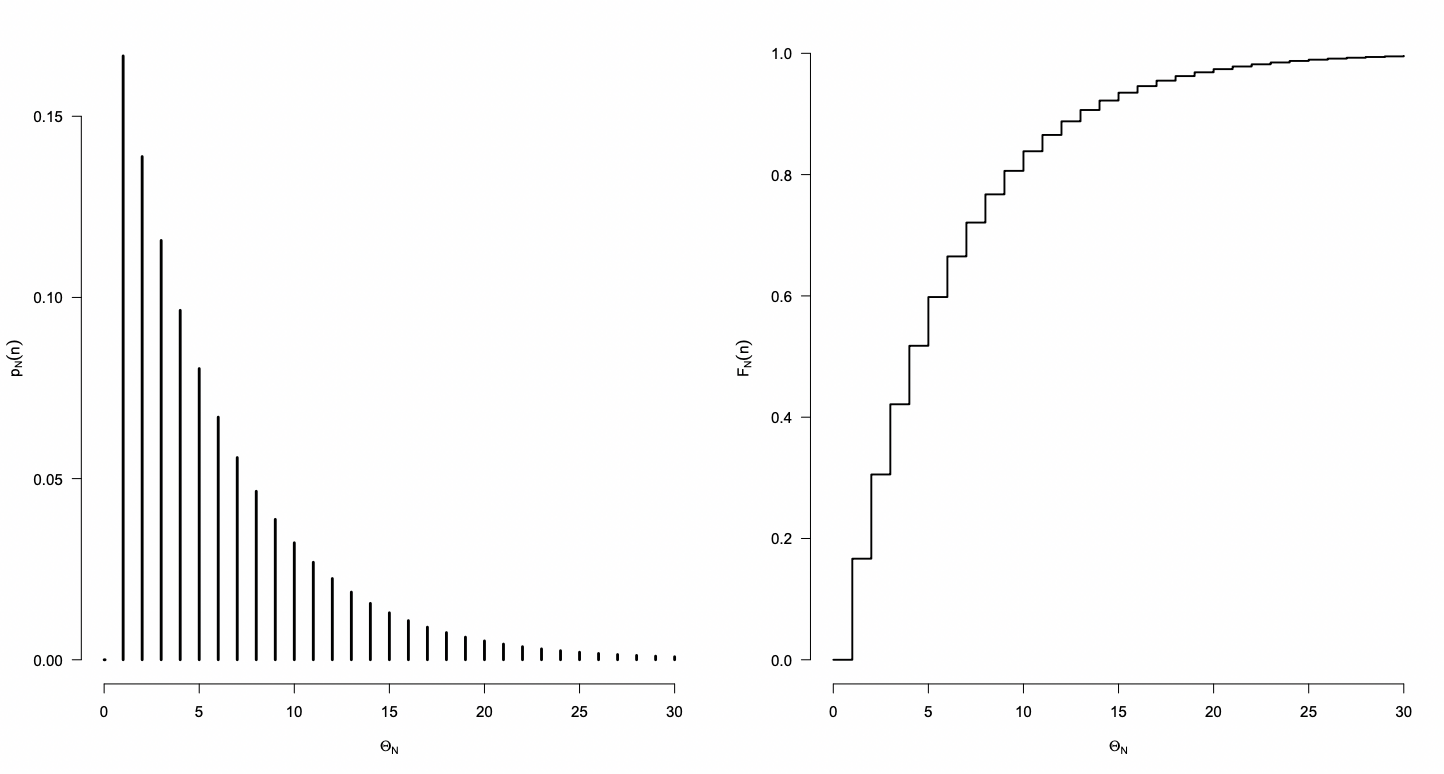
Dada una secuencia Bernoulli, el número de experimentos hasta la ocurrencia del primer evento exitoso sigue una distribución geométrica.
Si el primer éxito ocurre en el n-ésimo experimento, los primeros n−1 fueron "fracasos". Si N es la variable aleatoria que representa el número de experimentos hasta el primer éxito, entonces:
P(N=n)=p(1−p)n−1,n=1,2,…
La función distribución esta dada por:
FN(n)=k=1∑[n]p(1−p)k−1=1−(1−p)[n]
para n≥1 y cero en otro caso.
Mientras que su valor esperado y varianza son:
Muchos problemas físicos de interés para ingenieros y científicos que implican las ocurrencias posibles de eventos en cualquier punto en el tiempo y/o en el espacio. Por ejemplo:
Los terremotos pueden ocurrir en cualquier momento y en cualquier lugar en una región con actividad sísmica en el mundo.
Las grietas por fatiga puede producirse en cualquier punto de una soldadura continua.
Los accidentes de tráfico pueden suceder en cualquier momento en una autopista.
Este problema puede ser modelado como secuencia Bernoulli, dividiendo el tiempo o el espacio en pequeños intervalos "apropiados" tal que solo un evento puede ocurrir o no dentro de cada intervalo (Ensayo Bernoulli).
Sin embargo, si el evento puede ocurrir al azar en cualquier instante de tiempo (o en cualquier punto del espacio), esto puede ocurrir más de una vez en cualquier momento o intervalo de espacio.
En tal caso, las ocurrencias del evento puede ser más apropiado el modelo con un proceso de Poisson o la secuencia Poisson.
Un evento puede ocurrir al azar y en cualquier instante de tiempo o en cualquier punto en el espacio.
La ocurrencia(s) de un evento en un intervalo de tiempo dado (o espacio) es estadísticamente independiente a lo que ocurra en otros intervalos (o espacios) que no se solapen.
La probabilidad de ocurrencia de un evento en un pequeño intervalo Δt es proporcional a Δt, y puede estar dada por νΔt, donde ν es la tasa de incidencia media del evento (que se supone constante).
La probabilidad de dos o más eventos en Δt es insignificante.
Bajo los supuestos anteriores, el número de eventos estadísticamente independientes en t (tiempo o espacio) esta regido por la función de probabilidad del modelo Poisson, donde la variable aleatoria Xt : número de eventos en el intervalo de tiempo (0,t).
P(Xt=x)=x!(νt)xe−νt=x!λxe−λ,x=0,1,2,…
donde ν es la tasa de ocurrencia media por unidad de tiempo y λ su espe-ranza en (0,t) :
En un Proceso de Poisson el tiempo transcurrido entre la ocurrencia de eventos puede ser descrito por una distribución exponencial.
Si T1 representa al tiempo transcurrido hasta la ocurrencia del primer evento en un Proceso de Poisson, el evento (T1>t) implica que en el intervalo (0,t) no ocurren eventos, es decir,
P(T1>t)=P(Xt=0)=0!(νt)0e−νt=e−νt,
con
Xt∼Poisson(νt)
Por lo tanto la función de distribución de probabilidad acumulada de T1 esta dada por:
FT1(t)=P(T1≤t)=1−P(T1>t)=1−e−νt
Su función densidad se obtiene como sigue:
fT1(t)=dtdFT1(t)=νe−νt
que corresponde a la función densidad de una variable aleatoria con distribución exponencial.
Esta distribución al igual que la geométrica tiene la propiedad de la carencia de memoria, es decir, si T∼Exponencial(ν) entonces se tiene que
P(T>t+s∣T>s)=P(T>t)
Este resultado, nos permite asumir que todos los tiempos entre eventos Poisson (νt) distribuyen Exponencial (ν).
Carencia de memoria
La carencia de memoria es una propiedad que indica que la probabilidad de que un evento ocurra en el futuro no depende de cuánto tiempo ha pasado desde el último evento.
En resumen, una variable aleatoria X con distribución Exponencial de parámetro ν>0, tiene función densidad y de distribución:
Una variable aleatoria X con distribución Exponencial de parámetro ν>0, se llama trasladada en a si su función densidad y de distribución acumulada son
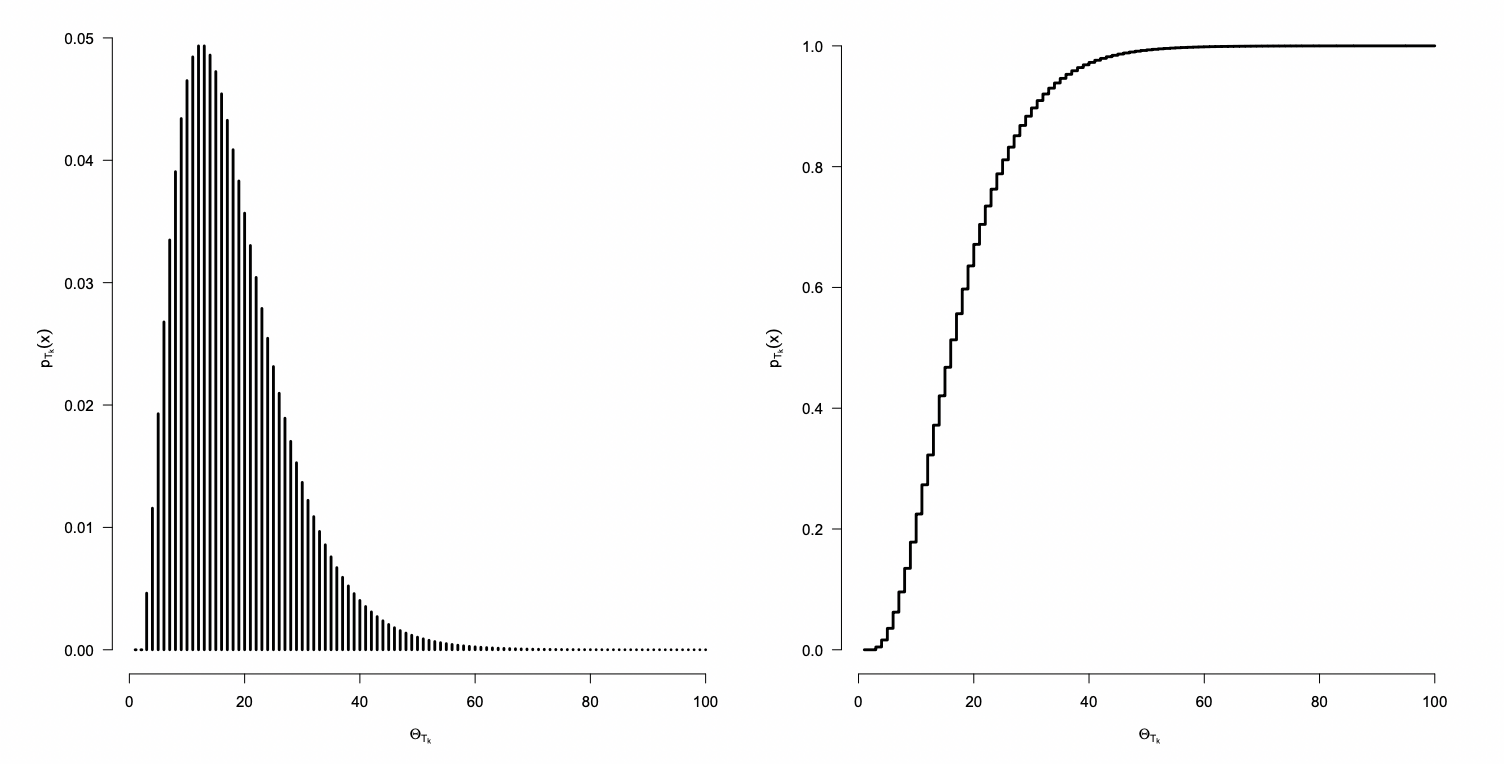
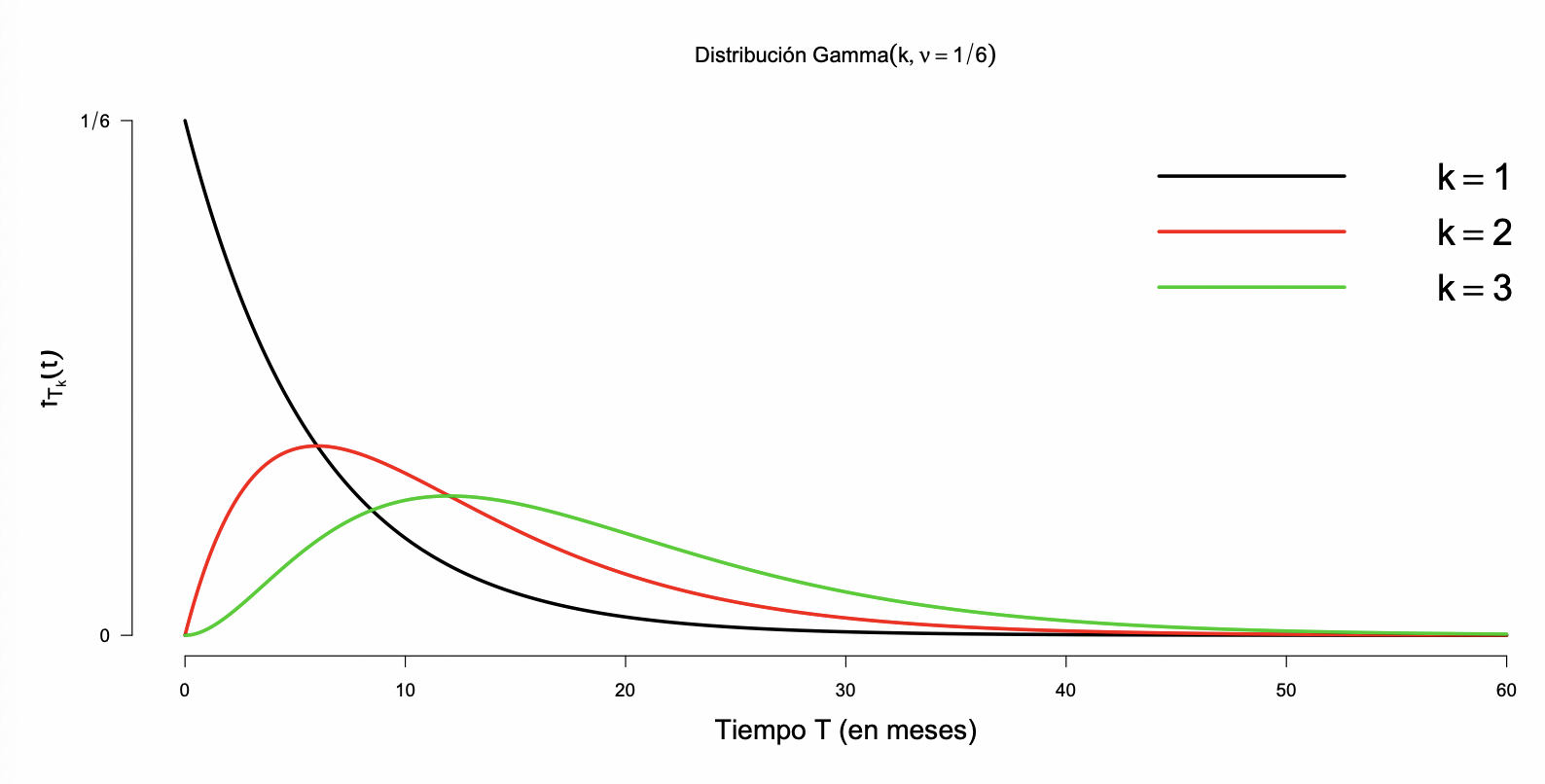
En un Proceso de Poisson el tiempo transcurrido hasta la ocurrencia del k-ésimo evento puede ser descrito por una distribución Gamma.
Si Tk representa al tiempo transcurrido hasta la ocurrencia del k ésimo evento en un Proceso de Poisson, el evento (Tk>t) implica que en el intervalo (0,t) ocurren a lo más k−1 eventos, es decir,
P(Tk>t)=P(Xt≤k−1)=x=0∑k−1x!(νt)xe−νt
Luego, su función de distribución acumulada esta dada por:
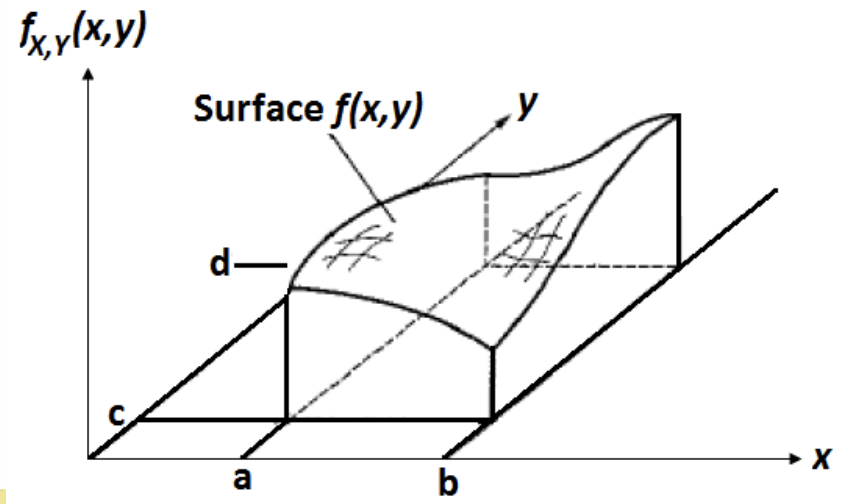
Cuando hay dos variables aleatorias X e Y, puede haber una relación entre ellas.
En particular, la presencia o ausencia de relación estadística lineal se determina observando el primer momento conjunto de X e Y definido como
E(XY)=∫−∞∞∫−∞∞xy⋅fX,Y(x,y)dxdy
Si X e Y son estadísticamente independientes, entonces
E(XY)=∫−∞∞∫−∞∞xy⋅fX(x)⋅fY(y)dxdy=E(X)⋅E(Y)
La covarianza corresponde al segundo momento central y se define como:
Cov(X,Y)=E[(X−μX)(Y−μY)]=E(X⋅Y)−μX⋅μY
Si X e Y son estadísticamente independientes, entonces
Cov(X,Y)=0
Nota
El significado físico de la covarianza se puede inferir de la ecuación:
Si Cov(X,Y) es grande y positiva, los valores de X e Y tienden a ser grandes (o pequeños) en relación a sus respectivos medias.
Si Cov(X,Y) es grande y negativo, los valores de X tienden a ser grandes con respecto a su media, mientras que los de Y tienden a ser pequeños y viceversa.
Si Cov(X,Y) es pequeña o cero, la relación (lineal) entre los valores de X e Y es poca o nula, o bien la relación es no lineal.
La covarianza mide el grado de asociación lineal entre dos variables, pero es preferible su normalización llamada correlación para poder cuantificar la magnitud de la relación.
La correlación esta definida como:
Cor(X,Y)=σX⋅σYCov(X,Y)
Este coeficiente toma valores en el intervalo (−1,1).
El valor esperado de una variable aleatoria Y condicionado a la realización x de una variable aleatoria X esta dado por
E(Y∣X=x)=⎩⎨⎧y∈ΘY∣X=x∑y⋅P(Y=y∣X=x),∫y∈ΘY∣X=xy⋅fY∣X=x(y)dy, caso discreto caso continuo
Por otra parte, para una función de Y, llamemos h(Y), el valor esperado condicional esta dado por
E[h(Y)∣X=x]=⎩⎨⎧y∈ΘY∣X=x∑h(y)⋅P(Y=y∣X=x),∫y∈ΘY∣X=xh(y)⋅fY∣X=x(y)dy, caso discreto caso continuo
Teorema de probabilidades totales para el valor esperado
Preparate (mentalmente) para el teorema de probabilidades totales para el valor esperado condicional:
E(X)=⎩⎨⎧y∈ΘY∑x∈ΘX∣Y=y∑x⋅pX∣Y=y(x)pY(y),∫y∈ΘY[∫x∈ΘX∣Y=yx⋅fX∣Y=y(x)dx]fY(y)dy,∫y∈ΘYx∈ΘX∣Y=y∑x⋅pX∣Y=y(x)fY(y)dy,y∈ΘY∑[∫x∈ΘX∣Y=yx⋅fX∣Y=y(x)dx]pY(y), Caso Discreto-Discreto Caso Continuo-Continuo Caso Discreto-Continuo Caso Continuo-Discreto
Predecir el valor de una variable aleatoria a partir de otra es un problema común en estadística. Consideremos primero la siguiente situación: "Predecir la realización de una variable aleatoria Y". El "mejor" valor c para predecir la realización de Y se puede obtener minimizando el error cuadrático medio definido como
ECM=E[(Y−c)2]
Nota
La constante c que minimiza el ECM es E(Y).
Si ahora queremos predecir Y basado en una función de una variable aleatoria X, llamemos h(X), que minimice el error cuadrático medio definido como
ECM=E{[Y−h(X)]2}=E(E{[Y−h(X)]2∣X})
Entonces, la función h(X) que minimiza ECM necesariamente debe corresponder a E(Y∣X).
Por ejemplo, si X e Y distribuyen conjuntamente según una Normal bivariada, entonces el mejor predictor Y basado en X es una función lineal dada por