Inferencia estadística
Definiciones y propiedades
En los capítulos previos hemos visto de manera introductoria como, dada una distribución de una variable aleatoria y el valor de sus parámetros, obtener probabilidades.
El calculo de probabilidades depende del valor de los parámetros. Por tanto, nos interesa disponer de métodos que permitan seleccionar adecuadamente valores de estos para las distribuciones de importancia práctica.
Para realizar lo anteriormente expuesto, requerimos información "del mundo real". Por ejemplo, datos referente a la pluviosidad en cierta área, intensidad y frecuencia de los movimientos telúricos, conteos, velocidades y flujo de vehículos en cierta intersección o vía, etc.
Con base a estos datos, los parámetros pueden ser estimados estadísticamente, y con información sobre el fenómeno inferir la distribución de probabilidad.
La estimación clásica de parámetros consiste en dos tipos:
- Puntual: simplemente indica un valor único, basado en los datos, para representar el parámetro de interés.
- Intervalar: entrega un conjunto de valores (intervalo) donde el parámetro puede estar con cierto nivel de confianza.
Para un estimador puntual, las siguientes propiedades son deseables:
- Insesgamiento: valor esperado del estimador sea igual al parámetro de interés.
- Consistencia: implica que si , el estimador converge al parámetro (propiedad asintótica).
- Eficiencia: se refiere a que la varianza del estimador. Dado un conjunto de datos, es más eficiente que para estimar si tiene menor varianza.
- Suficiencia: un estimador se dice suficiente si utiliza toda la información contenida en la muestra para estimar el parámetro.
Métodos de estimación
Método de los Momentos
En términos generales, el método propone igualar los momentos teóricos no centrales de una variable aleatoria denotados por , con los momentos empíricos, basados en los datos, , y despejar los parámetros de interés. Es decir,
Método de Máxima Verosimilitud
Otro método de estimación puntual es el denominado método de máxima verosimilitud (MV). En contraste con el método de los momentos, el método de máxima verosimilitud deriva directamente en estimador puntual del parámetro de interés.
Sea variable aleatoria con función de probabilidad , donde es el parámetro de interés. Dada una muestra (es decir, valores observados) , nos preguntamos cuál es el valor más probable de que produzca estos valores. En otras palabras, para los diferentes valores de , cuál es el valor que maximiza la verosimilitud de los valores observados .
La función de verosimilitud de una muestra aleatoria , es decir, independiente e idénticamente distribuida es:
Se define el estimador de máxima verosimilitud (EMV) como el valor de que maximiza la función de verosimilitud . Es decir, es la solución de
Maximizar es equivalente a maximizar , es decir,
Si la función de distribución (discreta o continua) depende de más de un parámetro, digamos , los EMV respectivos son las soluciones de las ecuaciones:
Los EMV son estimadores que poseen las propiedades deseables descritas anteriormente. En particular, para grande, son "los mejores" estimadores (en el sentido de varianza mínima).
Propiedades
- Asintóticamente Insesgados: , cuando .
- Varianza alcanza la cota de Cramer-Rao:
con .
- Distribución Asintótica: Normal.
- Invarianza: Si es el estimador máximo verosímil de , entonces es el estimador máximo verosímil de cuya distribución asintótica es
Prueba de Hipótesis
Una prueba de hipótesis es un método estadístico inferencial para la toma de decisiones sobre una población en base a la información proporcionada por los datos de una muestra. La inferencia puede hacerse con respecto a uno o más parámetros de la población o también para un modelo de distribución.
Una hipótesis es una afirmación con respecto a uno o más parámetros de una población.
Usualmente son dos las hipótesis que se contrastan son:
- Hipótesis nula, . Este tipo de hipótesis es la que se somete a prueba.
- Hipótesis alternativa, . Este tipo de hipótesis es la que se acepta si se rechaza la hipótesis nula.
Cuando interesa inferir sobre el valor de un parámetro de la población las hipótesis a contrastar son generalmente:
Procedimiento
Los pasos necesarios en las pruebas de hipótesis son:
- Defina la hipótesis nula y alternativa.
- Identificar la prueba estadística adecuada y su distribución.
- Basado en una muestra de datos observados estime el estadístico de prueba.
- Especifique el nivel de significancia.
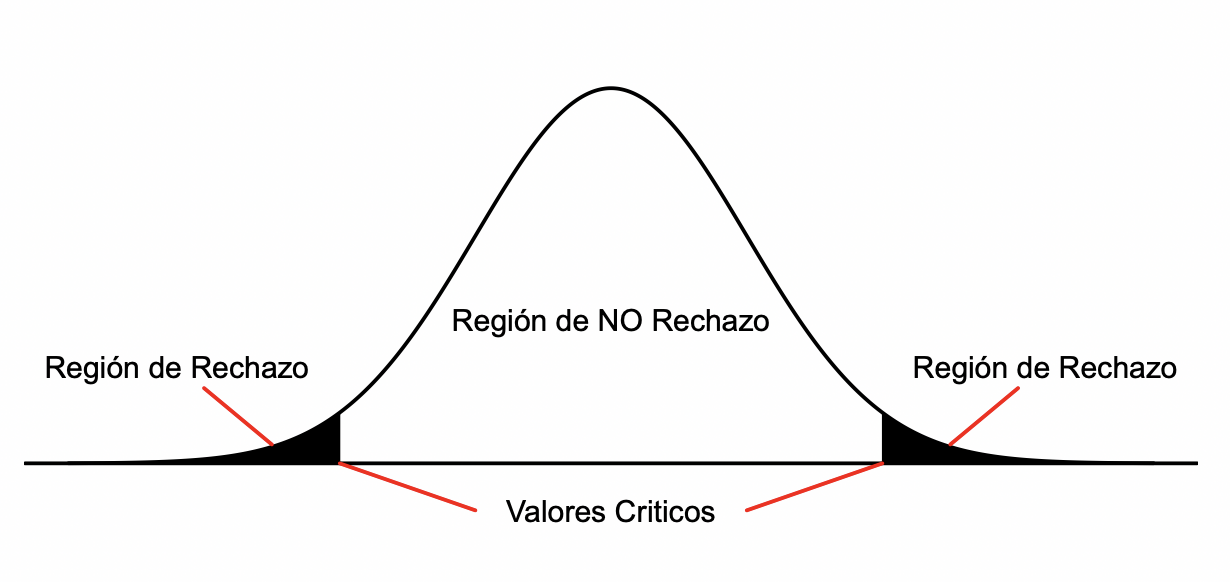
Dado que el estadístico de prueba es una variable aleatoria, la probabilidad de una decisión errónea puede ser controlada. Los errores que se pueden cometer son:
- Error Tipo I: Se rechaza dado que era correcta. La probabilidad de Error Tipo I se denota como , la cual corresponde al nivel de significancia de la prueba de hipótesis.
- Error Tipo II: No se rechaza dado que no era correcta. La probabilidad real de cometer Error Tipo I se conoce como valor-.
Intervalos de confianza
Intervalos de confianza para la media
Sea una muestra aleatoria de una población cuya distribución es .
Un estimador insesgado y consistente para esta dado por
Intervalo de Confianza para con conocido
Tenemos que
Luego, se puede mostrar que
Intervalo de Confianza para con desconocido
Tenemos que
Luego, se puede mostrar que
Tamaño de la muestra
Como se aprecia en la construcción de los Intervalos de Confianza, el tamaño de muestra es fundamental.
Al observar el Intervalo de Confianza para , se aprecia que el semiancho esta dado por:
Lo anterior se conoce como Error de Estimación.
Por lo tanto, para una precisión dada, es posible determinar el tamaño de muestra necesaria, con y fijos, dado por
Alternativamente también se puede determinar un tamaño muestral a partir controlando por los errores tipo I y II de una prueba de hipótesis.
Intervalos de confianza para la varianza
Consideremos nuevamente una muestra aleatoria proveniente de una población cuya distribución es .
Un estimador insesgado y consistente para esta dado por:
Tenemos que
Luego, se puede mostrar que
Intervalos de confianza asintóticos
Sea el estimador de máxima verosimilitud de un parámetro . A partir del siguiente pivote
se tiene que
con la varianza asintótica de .
Intervalos de confianza asintóticos: proporción
Por ejemplo, consideremos una muestra aleatoria proveniente de una población cuya distribución es .
Un estimador insesgado y consistente para esta dado por:
Tenemos que
Luego,
Tests de bondad de ajuste
Test de Kolmogorov-Smirnov
Supongamos que queremos evaluar la calidad de ajuste del modelo .
con función de distribución acumulada empírica y función de distribución acumulada teórica del modelo que se quiere ajustar.
En R la función ks.test() realiza la comparación y calcula el valor .
Test de Chi-Cuadrado
Considere una muestra de valores observados de una variable aleatoria y suponga una distribución de probabilidad subyacente. El test de bondad de ajuste compara las frecuencias observadas de valores (o intervalos) de la variable con sus correspondientes frecuencias teóricas que calculados suponiendo la distribución teórica.
Para evaluar la calidad del ajuste se usa el siguiente estadístico de prueba:
cuya distribución se aproxima por una .
Si los parámetros de la distribución son desconocidos, estos deben ser estimados a partir de los datos y debe ser descontado de los grados de libertad de la distribución (por cada parámetro estimado). Si el estadístico de prueba , la hipótesis nula que los datos provienen de la distribución escogida es rechazada.
El parámetro , con el número de estadísticos necesarios para estimar los parámetros.
Se recomienda aplicar este test cuando y .
En R la función chisq.test() realiza la comparación y calcula el valor- para el caso .
Regresión lineal
Introducción
La Inferencia vista anteriormente, puede ser abordada desde el punto de vista de Modelos Estadísticos. Así por ejemplo, si es una muestra aleatoria de una distribución Normal con media y varianza ambos parámetros desconocidos.
Este experimento se puede escribir en términos del siguiente modelo:
donde tienen distribución normal con media cero y varianza .
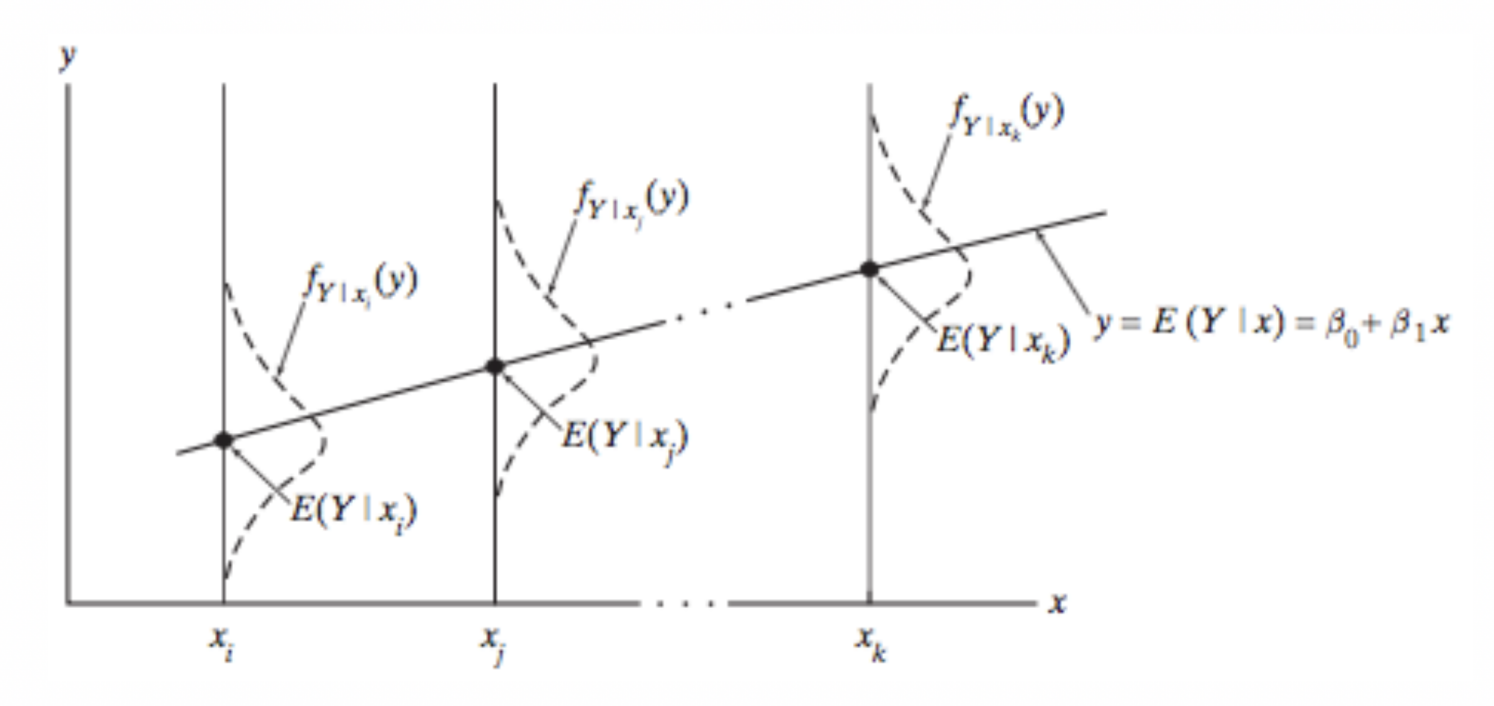
Al permitir que la media de varíe de manera funcional con respecto a una covariable de la siguiente manera:
Obtenemos el modelo de regresión simple. Se llama a
a la curva de regresión de sobre . Si la relación funcional es lineal en los parámetros, es decir,
entonces el modelo se llama regresión lineal simple, y la curva de regresión esta dada por .
En cambio si
el modelo sería de regresión no lineal simple, y la curva de regresión esta dada por .
Regresión lineal simple
Consideremos el modelo de regresión lineal simple,
Algunos supuestos son:
- Linealidad: La media condicional de sobre es lineal
- Homocedasticidad: La varianza asociada a es la misma para todo e iguala .
- Independencia: Las distribuciones condicionales son variables aleatorias independientes para todo .
- Normalidad: tiene distribución normal para todo .
La interpretación de los parámetros del modelo son las siguientes:
- : intercepto, .
- : pendiente, corresponde a la variación de cuando aumenta en una unidad.
Coeficiente de determinación
Coeficiente de determinación :
Coeficiente de determinación ajustado:
Ambos se interpretan como la proporción de variación total que es explicada por el modelo de regresión lineal.
Test T y Test F
Los test T y test F son pruebas estadísticas utilizadas en el análisis de regresión lineal para evaluar la significancia de los parámetros estimados y el modelo en su conjunto, respectivamente.
El test T se usa para probar la hipótesis nula de que el coeficiente de una variable independiente en una regresión lineal es igual a cero (lo que implica que la variable no tiene efecto sobre la variable dependiente). La fórmula para el estadístico T es:
Donde:
- es el estimador del coeficiente de la variable independiente .
- es el error estándar del estimador .
La hipótesis nula () y la hipótesis alternativa () son:
Si el valor p asociado al estadístico T es menor que el nivel de significancia elegido (comúnmente 0.05), rechazamos la hipótesis nula, lo que sugiere que la variable independiente tiene un efecto significativo sobre la variable dependiente.
El test F se utiliza para probar la hipótesis nula de que un modelo de regresión lineal no tiene capacidad explicativa, es decir, que todos los coeficientes de las variables independientes son iguales a cero simultáneamente. Esto se hace comparando el modelo propuesto con un modelo más simple, usualmente el modelo que solo incluye el término de intercepción. La fórmula para el estadístico F es:
Donde:
- es la suma de cuadrados residuales del modelo restringido (solo con intercepción).
- es la suma de cuadrados residuales del modelo completo.
- es el número de parámetros estimados en el modelo completo excluyendo el término de intercepción.
- es el número total de observaciones.
La hipótesis nula () y la hipótesis alternativa () para el test F son:
Si el valor p asociado al estadístico F es menor que el nivel de significancia elegido, rechazamos la hipótesis nula, lo que indica que el modelo en conjunto proporciona una mejor explicación de la variabilidad de la variable dependiente que el modelo sin ninguna de las variables independientes.
Ambos tests son fundamentales para entender la significancia de los coeficientes individuales y del modelo de regresión en su conjunto.